Interval Deletion in Binary Search Tree
Distinguished professor Fabinaris Suchbaum from Max Planck Institute for Software Systems in Saarbrücken is a well recognized expert on binary search trees (BST) and their improvements. Recently he has been contacted by Data4Ever company. To improve the performance of their latest database, the company needs an efficient data structure which supports a deletion of records whose key is within a given range of values. The solution delivered by professor Suchbaum is a binary search tree where the requested operation is designed as follows. Given a BST, which contains distinct keys, and interval I, the interval deletion works in two phases. During the first phase it removes all nodes whose key is in I and all edges adjacent to the removed nodes. Let the resulting graph contain k connected components T1,...,Tk. Each of the components is a BST where the root is the node with the smallest depth among all nodes of this component in the original BST. We assume that the sequence of trees Ti is sorted so that for each i < j all keys in Ti are smaller than keys in Tj. During the second phase, trees Ti are merged together to form one BST. We denote this operation by Merge(T1,...,Tk). Its output is defined recurrently as follows:
- For an empty sequence of trees, Merge() gives an empty BST.
- For a one-element sequence containing a tree T, Merge(T) = T.
- For a sequence of trees T1,...,Tk where k > 1, let a1< a2< ... < an be the sequence of keys stored in the union of all trees T1,...,Tk, sorted in ascending order. Moreover, let m = ⌊(1+k)/2⌋ and let Ts be the tree which contains am. Then, Merge(T1,...,Tk) gives a tree T created by merging three trees Ts, TL = Merge(T1,...,Ts-1) and TR = Merge(Ts+1,...,Tk). These trees are merged by establishing the following two links: TL is appended as the left subtree of the node storing the minimal key of Ts and TR is appended as the right subtree of the node storing the maximal key of Ts.
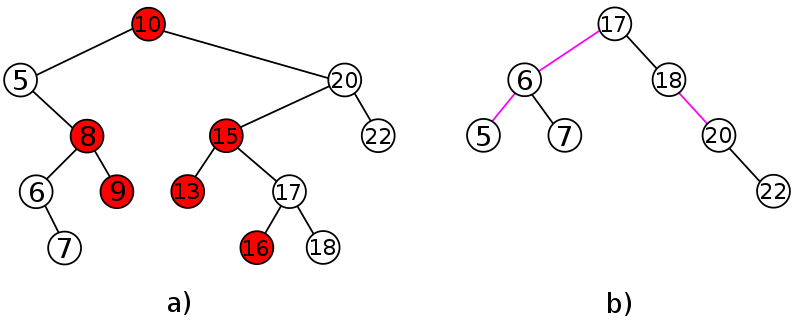
Image 1. a) A binary search tree containing 13 distinct keys. Interval deletion is called for the range [8, 16]. The nodes that are removed by the first phase are colored in red. Four connected components emerge: T1 storing key 5, T2 storing keys 6 and 7, T3 storing keys 17 and 18, and T4 storing keys 20 and 22. b) Merge(T1, T2, T3, T4) is applied during the second phase. The magenta edges are added to form the resulting BST T. Since (1+7)/2=4 and the fourth key in the sequence 5,6,7,17,18,20,22 is key 17, which belongs to T3, the root of T3 becomes the root of T. |
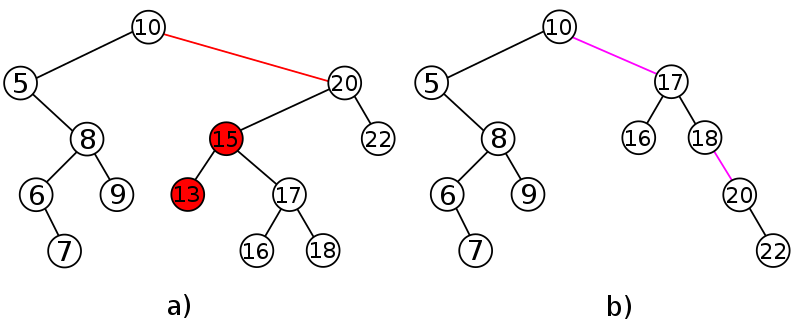
Image 2. a) The binary search tree from Image 1a). This time, interval deletion is called for the range [13, 15]. The edge between nodes storing keys 10 and 20 is removed because 10 < 13 and 15 < 20. b) Three connected components are merged. |
The task
Implement the operation of interval deletion. Test the operation by building a BST using N inserts,
followed by performing one interval deletion.
Input
The first input line contains integer N determining the number of keys to be inserted into an empty BST. The second input line contains N distinct integers separated by spaces. The integers represent keys to be inserted into the BST (in the order they are listed in). The third input line contains integers Rmin and Rmax, separated by a space. The interval deletion removes each inserted key K such that Rmin ≤ K ≤ Rmax. The keys to be inserted are values from 1 to 107. It is ensured that the resulting BST has at least 2 nodes. It holds Rmin ≤ Rmax and N ≤ 106.
Output
The output consists of one line containing integers D and H separated by space. Integer D is the depth of the final BST, obtained after performing N inserts and one interval deletion. Integer H is the total number of nodes of depth D−1 in the final BST.
Example 1
Input6 3 1 4 2 6 7 3 5Output
3 1
Example 2
Input13 10 5 8 6 9 7 20 15 22 13 17 16 18 8 16Output
3 3Example 2 is visualized in Image 1.
Example 3
Input20 187 146 95 128 200 11 186 179 189 135 94 16 51 45 105 194 145 68 57 77 150 190Output
7 2
Public data
The public data set is intended for easier debugging and approximate program correctness checking. The public data set is stored also in the upload system and each time a student submits a solution it is run on the public dataset and the program output to stdout and stderr is available to him/her.
Link to public data set