L-systém
L-systém je formální nástroj pro práci s řetězci znaků vyvinutý pro popis růstu rostlin a morfologie jednoduchých organizmů.L-systém obsahuje neprázdnou množinu znaků A nazývanou abeceda, dále obsahuje přepisovací pravidla a počáteční řetězec R1 nazývaný semínko.
Simulace růstu rostliny/organizmu pomocí L-systému probíhá v krocích. V prvním kroku se ze semínka R1 pomocí přepisovacích pravidel vygeneruje řetězec R2, ve druhém kroku se z řetězce R2 pomocí přepisovacích pravidel vygeneruje řetězec R3 atd. Obecně, v k-tém kroku se z řetězce Rk vygeneruje řetězec Rk+1. Posloupnost řetězců (R1, R2, R3, ...) je tím pro daný L-systém jednoznačně určena.
Každé přepisovací pravidlo nahrazuje jeden znak abecedy neprázdnou posloupností znaků abecedy. Řetězec Rk+1 (k ≥ 1) vznikne tak, že v řetězci Rk se každý znak nahradí (přepíše) posloupností znaků příslušného pravidla. Přepisování probíhá na všech znacích Rk simultánně. Například:
L-systém L1: Řetězce generované L-systémem L1:
Abeceda: {a, b, c} R1 = c
Pravidla: R2 = ba
a -> bcac R3 = cbcac
b -> c R4 = bacbabcacba
c -> ba R5 = cbcacbacbcaccbabcacbacbcac
Semínko: c ...
atd.
Syntaktický strom s hloubkou H L-systému definujeme takto:
Každý znak v každém řetězci R1, R2, ..., RH budeme považovat za uzel stromu. Pokud znak Y v řetězci Rk+1 (1 ≤ k < H) vznikl přepsáním znaku X v řetězci Rk pomocí některého pravidla, řekneme, že Y je bezprostředním potomkem X. Kořenem stromu bude zvláštní uzel R0, jehož bezprostředními potomky budou právě všechny jednotlivé znaky R1. Znaky řetězce RH budou listy stromu.
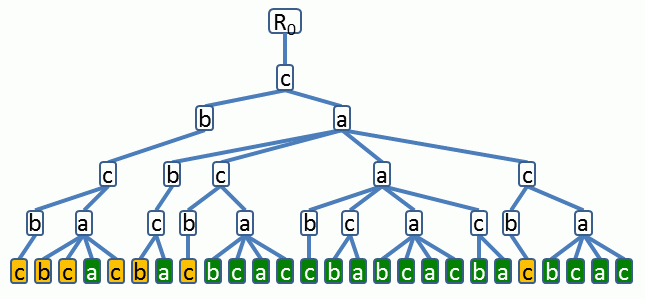
Obr 1. Syntaktický strom s hloubkou H = 5 L-systému L1.
Listy jsou obarveny podle filtrujícího řetězce aca, viz dále.
Pro daný L-systém, danou hloubku H jeho syntaktického stromu a daný filtrující řetězec máme určit počet zelených a oranžových listů.
Vstup
Nejprve je zadán L systém. První řádek vstupu obsahuje jediný řetězec představující abecedu A L-systému. Znaky se v řetězci neopakují, jejich ASCII kódy jsou v rozmezí 33 a 126 decimálně (mezera není součástí abecedy) a jsou uvedeny v libovolném pořadí.Dále následuje tolik řádků, kolik má abeceda A znaků. Na každém řádku je uvedeno jedno přepisovací pravidlo ve formátu
<znak><mezera><šipka><mezera><znaky>, kde
<znaky> je některý ze znaků abecedy A,
<mezera> je obyčejná mezera (znak s ASCII kódem 32 decimálně),
<šipka> je dvojice znaků "
->" (ASCII kódy 45 a 62 decimálně),<znaky> je libovolná neprázdná posloupnost nejvýše 20 znaků abecedy A.
Pro každý znak abecedy A existuje právě jedno pravidlo, pravidla mohou být uvedena v libovolném pořadí.
Na dalším řádku je uvedeno semínko, což je neprázdný řetězec s nejvýše 20 znaky abecedy A.
Na dalším řádku je uvedeno číslo H určující hloubku syntaktického stromu L-systému. Vstup je ukončen řádkem s neprázdným filtrujícím řetězcem, který je sestaven ze znaků abecedy. Kromě explicitně výše uvedených mezer neobsahuje vstup žádné další mezery nebo bílé znaky.
Počet uzlů v syntaktickém stromu nepřevýší 3 miliony, hloubka stromu nepřevýší 25.
Výstup
Na výstupu je jediný řádek se dvěma celými čísly oddělenými mezerou a představujícími počet zelených a oranžových listů (v tomto pořadí) v syntaktickém stromu daného L-systému s použitím daného filtrujícího řetězce.Příklad 1
Implementuje ukázku z textu.Vstup:
abc a -> bcac b -> c c -> ba c 5 acaVýstup:
19 7
Příklad 2
Vstup:D* D -> D* * -> * D*D* 1 **Výstup:
0 4
Příklad 3
Vstup:H% H -> %H % -> % H 5 %%%Výstup:
2 3
Příklad 4
Vstup:F+- F -> F+F--F+F + -> + - -> - F 4 FF+Výstup:
40 108
Poznámka
Obecně se L-systémy a jejich varianty definují ve větší obecnosti, než jsme jak je zavedli v této úloze. O interpretaci L-systémů a jejich aplikacích se čtenář dozví více na adrese http://algorithmicbotany.org/papers/ a v souvisejících dokumentech a stránkách.Veřejná data
Veřejná data k úloze jsou k dispozici. Veřejná data jsou uložena také v odevzdávacím systému a při každém odevzdání/spuštění úlohy dostává řešitel kompletní výstup na stdout a stderr ze svého programu pro každý soubor veřejných dat.