Maximum path
Let R be an unempty string over alphabet A = {a, b, c, ..., z}. We denote the first character of R by R(0), the second character of R by R(1), the third character of R by R(2) etc.Let K be a positive integer, K ≤ |R|. We define index vector associated with R and K to be any strictly increasing sequence of K integers X = (x0, x1, ..., xK−1) for which holds
0 ≤ x0, xK−1 ≤ |R|−1.
We define R-image of index vector X associated with R and K to be a sequence of K characters (c0, c1, ..., cK−1) for which holds
0 ≤ i ≤ K−1 ⇒ ci = R(xi).
We denote R-image of index vector X associated with R and K by symbol Im(X, R).
Example: Im((0,1,4,5), abacba) = (a, b, b, a).
We say that two index vectors X and Y associated with R and K are equivalent if Im(X, R) = Im(Y, R).
Example: R = abacba, K = 4. Index vectors X = (0,3,4,5) and Y = (2,3,4,5) associated with R and K are equivalent because Im(X, R) = Im(Y, R) = (a, c, b, a).
We represent each equivalence class T of index vectors associated with R and K by that element of T which is lexicographically smallest among all elements of T. We denote the representative of equivalence class T by symbol rep(T).
Example: R = abacbaa, K = 4. rep({(0,3,4,5), (2,3,4,5), (0,3,4,6), (2,3,4,6)}) = (0,3,4,5).
Let D and L be nonnegative integers. We define weighted directed graph G(R, K, D, L) as follows:
The nodes of G(R, K, D, L) are all equivalence classes of all index vectors associated with R and K. We say that node m is smaller than node n if Im(rep(m), R) is lexicographically smaller than Im(rep(n), R). There is a directed edge from node m to node n if all three following conditions hold:
1. m is smaller than n.
2. Hamming distance between Im(rep(m), R) and Im(rep(n), R) is smaller or equal to D.
3. There are at most L nodes w such that m is smaller than w and w is smaller than n.
The weight of the edge (m, n) is defined as follows:
Let rep(m) = (x0, x1, ..., xK−1) be the representative of the class m and let rep(n) = (y0, y1, ..., yK−1) be the representative of the class n. If there is an edge (m, n) its weight is equal to
x0 + x1 + ... + xK−1 + y0 + y1+ ... + yK−1.
In other words the weight of (m, n) is the sum of all components of rep(m) increased by the sum of all components of rep(n).
The task
The problem is to find the maximum weight of all directed paths in G(R, K, D, L). The weight of any directed path p is equal to the sum of all edge weights along p.
Input
Input contains two text lines. The first line contains string R, the second line contains numbers K, D, L in this order, separated by space. You may assume that following holds:1 ≤ D ≤ K ≤ |R| ≤ 50. Number of nodes of G(R, K, D, L) does not exceed 105, number of edges of G(R, K, D, L) does not exceed 106.
Output
Output contains one text line with single integer denoting the maximum weight of all directed paths in G(R, K, D, L).Example 1
Input:ccaabb 4 2 2Output:
78
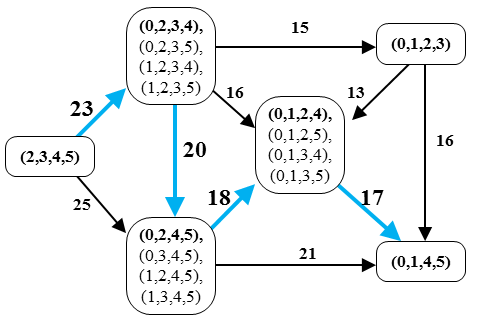 |
Image 1. There are exactly 15 different index vectors associated with R = ccaabb and K = 4. All those vectors are also listed in the picture which depicts the graph G(ccaabb, 4, 2, 2). Each node contains exactly one equivalence class of vectors associated with R and K. The representatives of each class are printed in bold. The maximum weight path is denoted by bold blue arrows and large edge weights. |
Example 2
Input:ccaabba 4 1 2Output:
97
Example 3
Input:ababababcdcdcdcdefefefef 6 1 1000Output:
3668
Example 4
Input:ababababcdcdcdcdefefefef 6 2 1000Output:
62435
The public data set is intended for easier debugging and approximate program correctness checking. The public data set is stored also in the upload system and each time a student submits a solution it is run on the public dataset and the program output to stdout a stderr is available to him/her.